不知不覺也過了兩個星期了,繼續加油吧!
我們前面講了好多和資訊檢索相關的內容和計算方式,不過有一個部分沒有提到,那就是評估檢索結果的方法。
這個部分乍看之下好像很簡單,不就是把真正相關的文章和檢索出來的文章比對一下而已嗎?不過我在找完資料之後才發現,原來還有這麼多重要的細節可以拿出來討論,我預計會分成兩天把它講完。
無論是在做機器學習或是任何研究的時候,評估任務都是非常重要的一環,而資訊檢索也不例外。我們需要把跑出來的結果量化成一個分數,才能用來決定這次做的好不好,哪裡需要調整。
首先,我們可以提出一個問題:什麼樣的檢索結果算是好的?
根據這兩周每天瘋狂上網找資料的體驗,做為使用者,我覺得好的檢索結果應該要包含兩個部分:
這兩個要求雖然不高,但要做到一個良好的評估指標,還需要注意一些細節的部份,我們可以先從基礎的概念開始。
記得之前上機器學習課程的時候,在評估 Classification 品質的部分有學過 Accuracy、Precision、Recall 這三個指標,沒想到在這邊又遇到了。
他們的定義應該不用再說一次了吧,我直接把公式列出來:
這三個指標在 IR 裡面的用法和之前學過的一樣,不過字面意義略有不同:
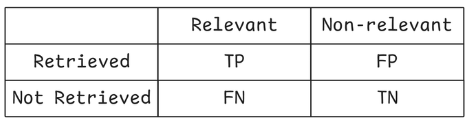
如表格所示,我們把欄位分為「是否被檢索到」和「是否相關」進行交叉比對,可以獲得這樣的解釋:
然而,在實際評估中通常不會用到 Accuracy,因為它有一個 bug,我們可以用一個例子來說明。
假設我們想要建立一個搜尋引擎,提高 Accuracy 的方法有兩種,要嘛盡量找到相關的文檔,要嘛盡量不要找到不相關的文檔。
但作為一個擅長摸魚的工程師,我們只能做到後面的部分,因為在海量的資料中,使用者想要找到的文檔往往只佔不到千分之一甚至更少的比例,所以只要這個搜尋引擎什麼結果都不要回傳,它的 Accuracy 就可以高達 99.9%。
這樣子的評估方式顯然不切實際,所以通常只會使用 Precision 和 Recall 來驗證我們的檢索做的好不好。
然而, Precision 和 Recall 這兩個指標會呈現反比關係,只要提升其中一個,另一個就會降下去,像下面這張圖一樣:
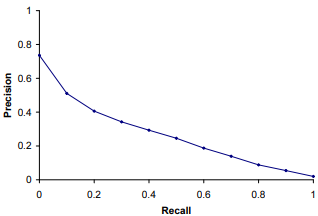
從 IR 的角度來解釋的話,會造成這個現象的原因是我們對兩者的期望方向不同。
以 non-rank 的檢索方式為例,當我們追求高品質的檢索結果,標準就會變的很嚴格,能夠被找到的文章相對少,但相關的比例非常高。這個時候 Precision 高,Recall 低,因為有些其實算相關只是沒有通過標準的文檔被遺漏掉了。
反之,當我們追求找到相關的文檔數量越多越好,這個時候標準變低了,很多只有一點點相關的文檔也被納入檢索到的文檔中,從結果來看雖然相關的文檔數量變多,也就是 Recall 變高,但同時整體品質也在降低,Precision 變的很差。
所以,我們會根據場景需求不同,決定偏重哪一種指標。舉例來說,一般的搜尋引擎需要傳回大量相關的文檔,就會偏重 Recall,而如果是要檢索較為專業的內容,譬如病例或法律判決書,我們肯定不希望傳回一堆垃圾還要自己再篩選,這個時候就會偏重 Precision。
ranking 的檢索方式也是如此,不過我們就放到明天再聊吧。
另外,我們可以補充一個用來綜合考慮 Precision 和 Recall 的指標:E-measure,它是從 F-measure ( 和 F1 score 公式一樣 ) 變過來的,大家都知道 F1 score 的公式是 F=2PR / (P+R),而 E-measure 則是加上了一個 β 的符號:
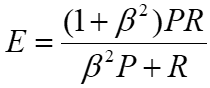
明天繼續把評估檢索的後半段講完吧。
推薦資料
https://www.cl.cam.ac.uk/teaching/1415/InfoRtrv/lecture5.pdf
https://web.fe.up.pt/~ssn/wiki/_media/teach/dapi/202021/lectures/dapi2021-evaluation-ir.pdf

